What is etcd?
etcd (pronounced et-see-dee) is an open-source, distributed key-value store that provides a way to store data that needs to be accessed by a distributed system or cluster of machines. etcd is widely used for configuration management, service discovery, and scheduler coordination of distributed systems or clusters of machines.
etcd itself is distributed across a cluster of machines. This means that the data stored in etcd is replicated and synchronized across multiple nodes in a network.
etcd is often associated with Kubernetes, where it serves as the primary data store for cluster information, configurations, and metadata. Understanding and troubleshooting etcd can be complex because it has several moving parts. etcd's sub-systems such as BoltDB, MVCC (Multi-Version Concurrency Control), Raft, WAL (Write-Ahead Log) and gRPC can be the cause of varied performance issues that range from leader election inconsistencies, network partitions, to fsync issues caused by the etcd database running out of space. All of these can put Kubernetes cluster stability at risk.
Why is etcd called etcd?
As detailed on the etcd documentation site: The name “etcd” originated from two ideas, the unix “/etc” folder and “d"istributed systems. The “/etc” folder is a place to store configuration data for a single system whereas etcd stores configuration information for large scale distributed systems. Hence, a “d"istributed “/etc” is “etcd”.
Who owns and maintains etcd?
etcd is an open-source project that is maintained and developed by the CoreOS team, which is now part of Red Hat. etcd was created by the CoreOS team in 2013, and was maintained by Red Hat engineers working alongside a team of peers from across the industry.
In 2018 Red Hat and the CoreOS team gave the etcd community project to the Cloud Native Computing Foundation (CNCF), a vendor-neutral organization housed under The Linux Foundation to drive the adoption of cloud-native systems. Red Hat remains involved in supporting etcd. With etcd used in every Kubernetes cluster, this neutrality of rehoming etcd in the CNCF community has been important for its future.
What is Raft in the context of etcd?
Raft refers to the consensus algorithm used for managing distributed replication and ensuring fault tolerance.
Consensus is a fundamental problem in fault-tolerant distributed systems. Consensus involves multiple servers agreeing on values. Once they reach a decision on a value, that decision is final.
Most consensus algorithms make progress when any majority of their servers is available - for example, a cluster of 5 servers can continue to operate even if 2 servers fail. If more servers fail, they stop making progress (but will never return an incorrect result).
Raft is a consensus algorithm that is designed to be easy to understand and implement, making it well-suited for distributed systems like etcd. A good explanation of Raft is available, here: Raft (thesecretlivesofdata.com).
Understanding the etcd Key-Value Store. Understanding the etcd data model
etcd stores data as key-value pairs, making it simple to store and retrieve data in systems such as Kubernetes. etcd uses a simple data model stored in flat K-V format in a 3-tuple structure that allows for more efficient storage and retrieval of data. Further details on the etcd data model can be found in the etcd documentation, see: Data model | etcd.
How does etcd work?
As mentioned above, etcd itself is distributed across a cluster of machines, it means that the data stored in etcd is replicated and synchronized across multiple nodes in a network.
Here's how etcd works:
- Cluster Formation: To start, you have multiple machines (nodes) that are part of an etcd cluster. These machines can be physical servers or virtual machines distributed across a network.
- Consensus Protocol: etcd employs a consensus protocol (typically Raft consensus algorithm) to ensure that all nodes in the cluster agree on the state of the data. This means that all nodes maintain the same data and ordering of operations.
- Data Replication: When data is written to etcd, it is replicated across multiple nodes in the cluster. This replication ensures fault tolerance and high availability. If one node fails, another node in the cluster can serve the data.
- Leader Election: In a Raft-based system, one of the nodes becomes the leader responsible for coordinating updates to the cluster. If the leader fails, a new leader is elected through the consensus protocol.
- Reads and Writes: Clients can read and write data to any node in the etcd cluster. The cluster ensures that the data is consistent across all nodes, regardless of which node is accessed.
- Scaling: As the load increases or more storage capacity is needed, you can scale out the etcd cluster by adding more nodes. This allows for horizontal scalability and improved performance.
Overall, by distributing etcd across a cluster of machines, you gain resilience, fault tolerance, and scalability, making it suitable for building reliable distributed systems.
Other key features and mechanisms of etcd include:
- Data Storage: etcd stores data in a distributed key-value store. Each key in etcd is unique and associated with a value. The data is typically stored in memory for fast access and durability, with periodic snapshots saved to disk for persistence.
- APIs: etcd provides a simple API for clients to interact with the cluster. Clients can perform operations like get, put, delete, watch, and transactional operations on the key-value store.
- Strong Consistency: etcd guarantees strong consistency for read and write operations. This ensures strict “serializability” and global ordering of events. This means that when a client reads data from etcd, it always sees the most recent value, and when a client writes data, the change is immediately visible to all clients.
- Watch Mechanism: etcd provides a watch mechanism that allows clients to subscribe to changes on specific keys. Clients receive notifications when the value of a watched key changes, enabling efficient event-driven programming.
- Security Features: etcd supports authentication and transport security to ensure that communication between nodes and clients is secure. It also provides role-based access control (RBAC) to control access to resources in the cluster.
A good overview that will answer many questions regarding how etcd works within the context of Kubernetes is available, see: How etcd works with and without Kubernetes (learnk8s.io).
What are the alternatives to etcd for Kubernetes? Can I replace etcd in Kubernetes?
etcd has long been the default choice for Kubernetes' data storage needs. However, new entrants are emerging as viable substitutes.
- Kine: supports various SQL databases like MySQL, PostgreSQL, SQLite, and dqlite. PostgreSQL is a particularly interesting alternative. Both postgres and etcd prioritize I/O performance in their storage design. Both systems optimize batch operations for sequential disk reads and writes. A good comparison is authored by Jinhua Luo here.
- Dqlite / SQLite: MicroK8s uses Dqlite (distributed SQLite) as its default datastore instead of etcd. Dqlite extends SQLite with high availability and network replication features. However, the community has reported problems with production workloads.
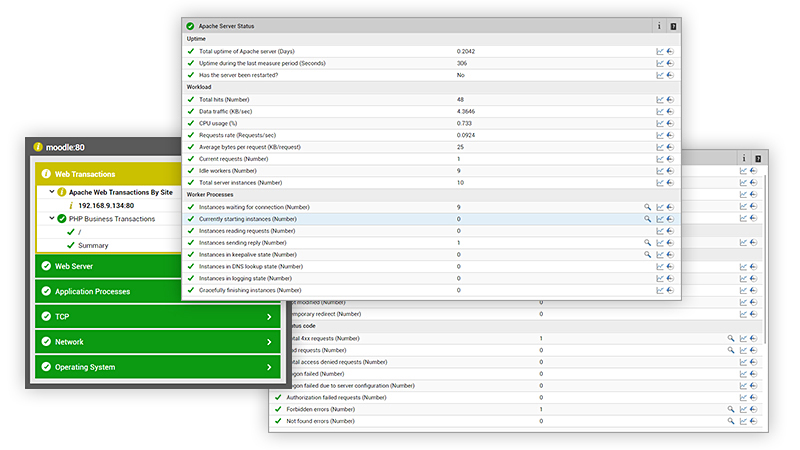
Why should you monitor etcd?
Monitoring etcd is crucial for several reasons:
- Ensure High Availability: etcd is often used to store critical configuration data and facilitate service discovery in distributed systems. Monitoring helps ensure that etcd is highly available and accessible to all components of the system. By monitoring key metrics such as cluster health and leader election latency, you can detect and resolve issues that may impact availability.
- Detect Performance Bottlenecks: Monitoring allows you to identify performance bottlenecks in the etcd cluster, such as high disk I/O, network latency, or increased client request latency. By monitoring storage, network, and client activity metrics, you can proactively address issues that may degrade performance and impact the responsiveness of your applications.
- Prevent Data Loss: etcd stores important data that is critical for the operation of distributed systems. Monitoring disk usage, Raft log size, and compaction rate helps prevent data loss by ensuring that etcd has sufficient storage space and is properly managing its data retention policies. Monitoring also helps detect any anomalies or errors that may lead to data corruption or loss.
- Optimize Resource Utilization: Monitoring resource usage, such as CPU, memory, and network bandwidth, allows you to optimize resource utilization in the etcd cluster. By identifying underutilized or overutilized resources, you can make informed decisions about scaling the cluster, allocating resources more efficiently, or optimizing configuration settings to improve performance and reduce costs.
- Ensure Security and Compliance: Monitoring security-related metrics, such as authentication failures and TLS handshake latency, helps ensure the security and compliance of the etcd cluster. By monitoring for unauthorized access attempts, unusual activity, or potential security vulnerabilities, you can detect and respond to security threats in a timely manner, helping to protect sensitive data and maintain regulatory compliance.